
An introduction to software quality

At FastRuby.io, we talk a lot about software quality. It’s how we determine whether a client is a good fit for an upgrade. The less technical debt a codebase has, the easier it is to maintain, and the more likely a Rails upgrade will go smoothly. But what determines whether software is “good quality”? In this article, we will talk about what software quality is, and explain the metrics that people use when talking about how to measure it.
What is software quality?
What software quality actually means can depend on who you ask. According to Wikipedia , which gets its definition from the former ISO/IEC 9126-1 (current ISO/IEC 25010) standard, software quality refers to two different metrics:
- Functional quality: how well software conforms to its functional requirements, i.e. it does what it is supposed to do
- Structural quality: how maintainable a piece of software is
The first metric is fairly straightforward so, in this article, we will talk about the second metric: the structural quality of software, or rather, its maintainability.
Maintainable software
What does it mean to have “maintainable” software? This definition seems to be more widely accepted. Maintainable software is easy to understand and modify. It tends to have two main characteristics:
- Code coverage: this refers to how much of your application is covered by tests. The more of your application is covered by tests, the easier it is to add features, refactor, or upgrade existing code.
- Code quality: this is the amount of technical debt a project has. Technical debt refers to the use of non-optimal solutions, for example, poor quality code, poor design, non-scalable solutions, etc. Technical debt is bad because so much developer time can be eaten up maintaining it, therefore costing businesses money.
Code Coverage
The first characteristic of maintainable software is code coverage. Code coverage is measured through the use of dynamic analysis tools. In general, these tools execute the code line by line and calculate what percentage of it is covered by the test suite. Some tools can calculate different coverage measurements. For example, Ruby’s coverage library, which is the backbone of SimpleCov , provides the following measurements:
- line coverage - the number of times each line was executed
- oneshot lines coverage - which lines are executed
- branches coverage - how many times each branch within each conditional in the code is executed
- methods coverage - how many times each method in the mode is executed
Code Quality
The second characteristic of maintainable software is code quality. Code quality is measured through the use of static analysis tools. A static code analysis program reads through each line of code in an application and assigns a complexity score to every file in a project. Some metrics that static analysis programs measure are:
- churn: a measure of how often a file changes. Churn is important to track because the frequency of how much a file changes can signify problems - lack of understanding of the problem that the code is trying to solve, poor design, code that is too complex.
- complexity: how hard it is to understand and reason through code. Like churn, how difficult a piece of code is to understand can signify problems. Complexity can make code harder to modify, and easier to break. Some measurements of complexity include:
- cyclomatic complexity: this is a count of the linearly independent paths through a piece of code
- the ABC metric: the number of assignments, branches, and conditionals in a piece of code
- code smells: a piece of code that can indicate a potential problem. Some examples of code smells are: bloated code, incorrectly applied design patterns, excessive coupling. Code smells can contribute to technical debt.
One example of a static analysis program is RubyCritic . RubyCritic is a wrapper around the tools Reek , Flay , and Flog , three tools that analyze the code according to these metrics.
Putting It All Together
Now that we have some definitions for software quality metrics, we can put them together to create an overall picture of a project’s quality. If you have read Michael Feathers’ article Getting Empirical about Refactoring or Sandi Metz’ article Breaking Up the Behemoth , you might have seen this file churn vs. complexity graph:
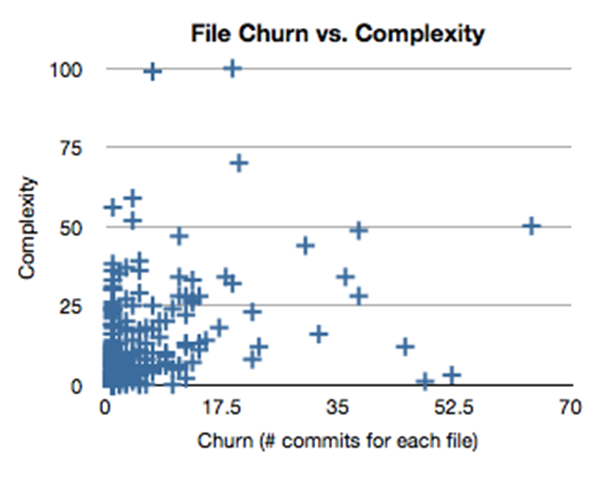 Complexity graph courtesy of Michael Feathers
Complexity graph courtesy of Michael Feathers
Here’s how the quadrants break down:
- Ideally, we want to have files in the lower left quadrant: files with low churn and low complexity don’t change very often and they’re easy to understand.
- Upper left quadrant: these are files with low churn and high complexity. It’s probably best to not touch these, since they do important stuff.
- Lower right quadrant: files with high churn and low complexity. These are the files that need to be changed often, usually stuff like config files and locals, etc.
- Upper right quadrant: files with high churn and high complexity. These are the files that probably should be refactored.
Conclusion
In this article, we talked about what software quality means, particularly when it comes to maintainable software. We learned what code coverage and code quality mean, and the difference between churn and complexity. Finally, we put together all our definitions and took a look at the file churn vs. complexity graph with a better understanding.
If you would like to learn more, here are some resources that helped me understand the topics we covered above (both by FastRuby.io’s founder Ernesto Tagwerker):