
Escaping the Tar Pit: Skunk v0.3.2 at RubyConf

This year I had the honor to speak at RubyConf in Nashville.
It was my second time attending the conference and first time as a speaker. I
talked about skunk, a gem to calculate the SkunkScore
of a module or set of modules.
Since its inception, skunk has changed quite a bit based on real usage in
our productized service for Rails upgrades . As a matter
of fact, the night before my talk I realized there was a BIG error in our
formula.
Here is a description of the problem and solution.
I was doing some tests the night before my talk and noticed unexpected results using Skunk version 0.3.0 . In my example, I wanted to show that simplifying a messy piece of code should show me an improvement in the skunk score average.
The problem was that as much as I improved the code, the skunk score average would only go up. This meant that the metric was lying to me. (And I was like WTF?!?!)

This is the project that I used for my example: https://github.com/fastruby/gggiiifff.com . It is an open source Roda application that basically consumes the Giphy API to find the gifs you are looking for.
When I ran skunk on this project, I got this summary:
SkunkScore Total: 0.71
Modules Analysed: 6
SkunkScore Average: 0.11833333333333333
Worst SkunkScore: 0.71 (models/query.rb)
In my test, I was trying to reduce complexity for the most complicated file
(models/query.rb) by removing code from that file (yes, I know that if I remove these
lines the application stops working, but it was a change to prove a concept)
In theory, removing methods from a module will improve its skunk score because then we have less code to maintain. (read more here to know how it works)
In practice, I was seeing the SkunkScore get worse with every git commit:
Base branch (master) average skunk score: 62.771
Feature branch (skunk-v-0-3-0) average skunk score: 62.791
Score: 62.79
The formula for AnalysedModule#skunk_score in Skunk v0.3.0
looks like this:
def skunk_score
return churn_times_cost.round(2) if coverage == PERFECT_COVERAGE
(churn_times_cost * (PERFECT_COVERAGE - coverage.to_i)).round(2)
end
# @return [Integer]
def churn_times_cost
safe_churn = churn.positive? ? churn : 1
@churn_times_cost ||= safe_churn * cost
end
The problem with this is that churn should not be considered when you are trying
to improve the skunk score, because churn has too much weight when calculating
the skunk score. If we were to include churn in the formula, we should make
that value weigh less.
One Example: Reducing Complexity
It might be easier to see this with an example. Let’s say that we have a module with a cost of 1000 and code coverage at 50%. Let’s say that we make 7 changes to the module and we reduce the cost by 100 each time.
This is what the skunk_score over time looks like:
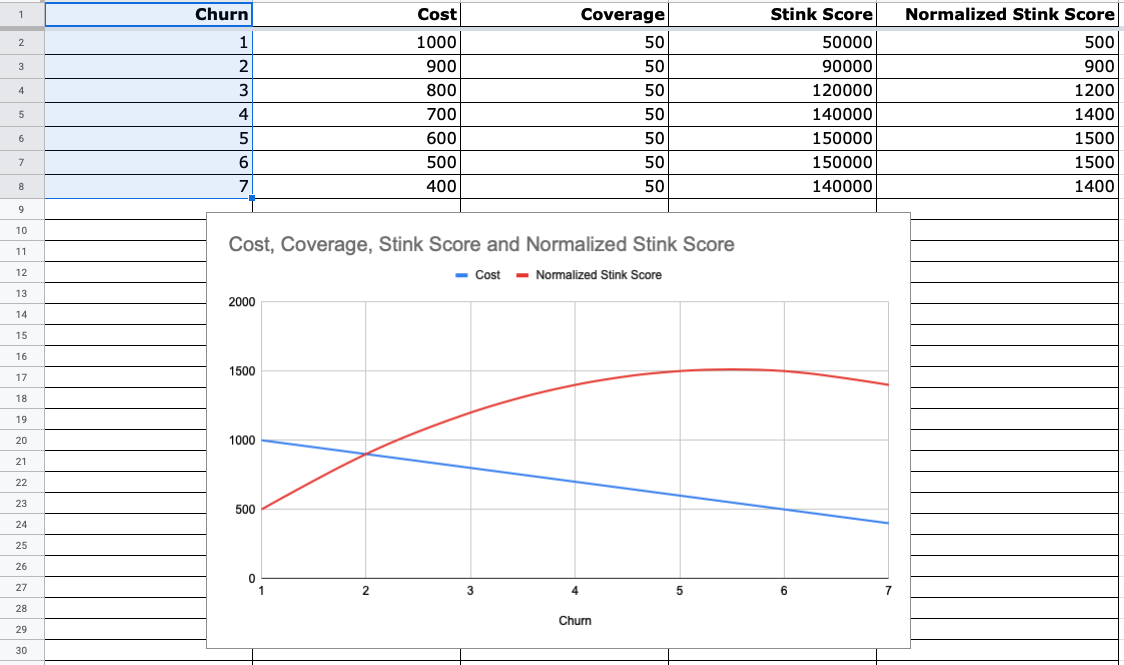
Every change that you make, reducing the cost by 100, is actually making the skunk score worse.
So, the night before my RubyConf talk, I decided it
would be best to remove churn from the skunk score formula.
This is what AnalysedModule#skunk_score looks like in Skunk v0.3.1 :
def skunk_score
return cost.round(2) if coverage == PERFECT_COVERAGE
(cost * (PERFECT_COVERAGE - coverage.to_i)).round(2)
end
It is pretty straight-forward: There is only one penalty factor which is relative to the lack of code coverage in the module.
Using this new formula and the same example, this is what the skunk_score over
time looks like:
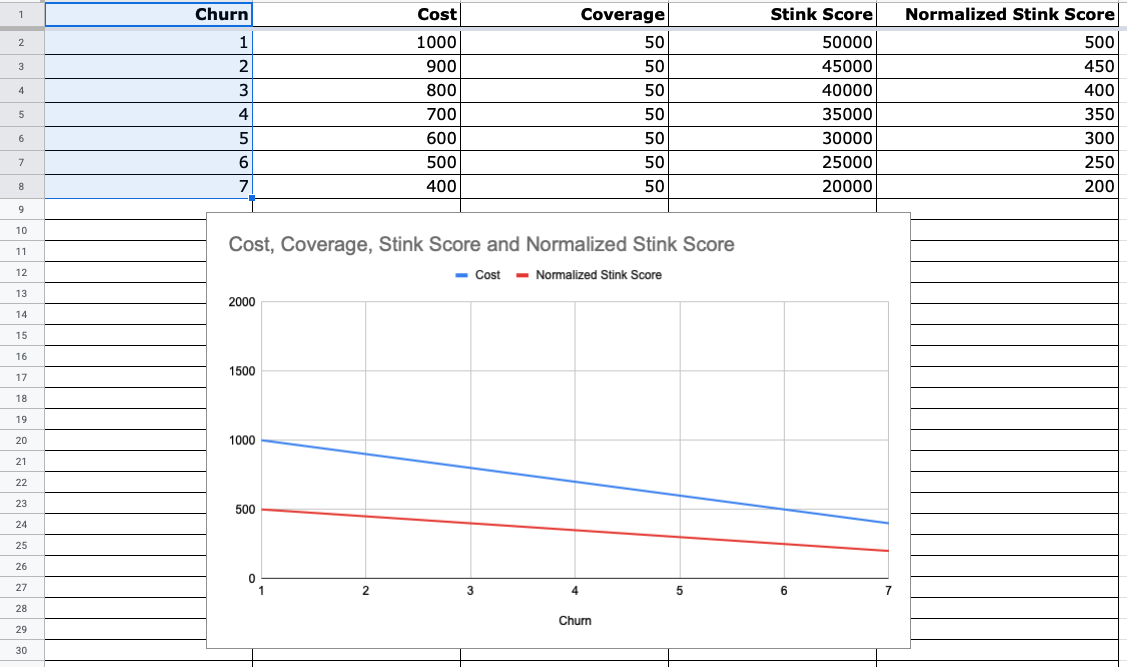
Now that looks more like what I expected!

Code Coverage Improvements
What does it look like if we make 4 changes to increase code coverage by 10% in every change?
If we are using version 0.3.0, this is what the skunk_score looks like:
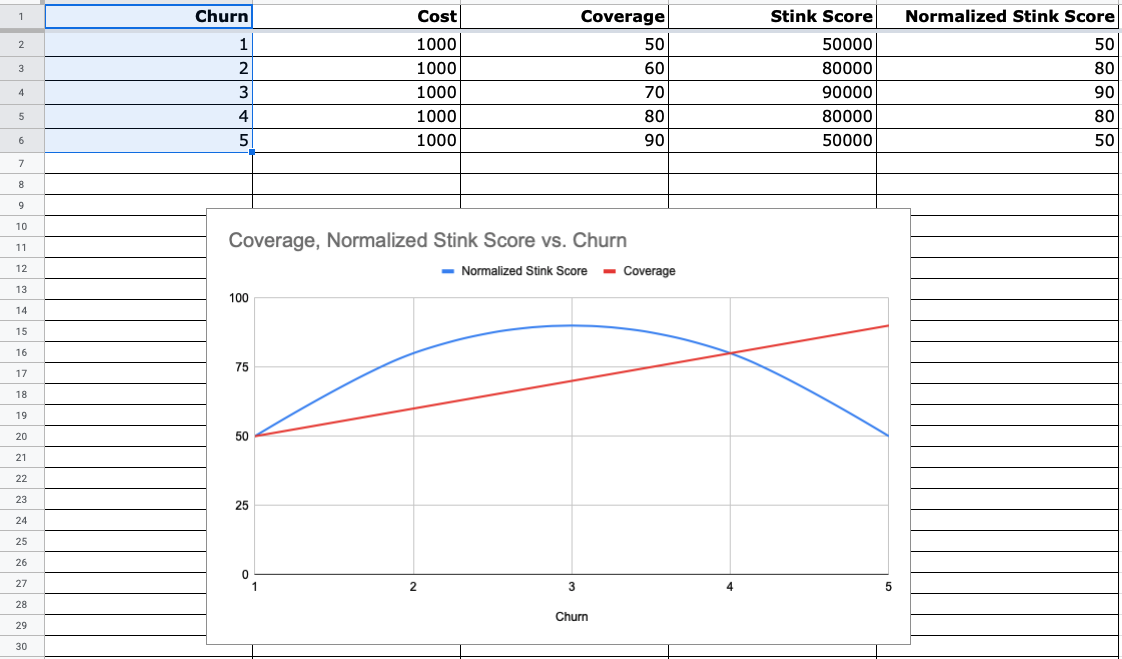
If we are using version 0.3.1, this is what the skunk_score looks like:
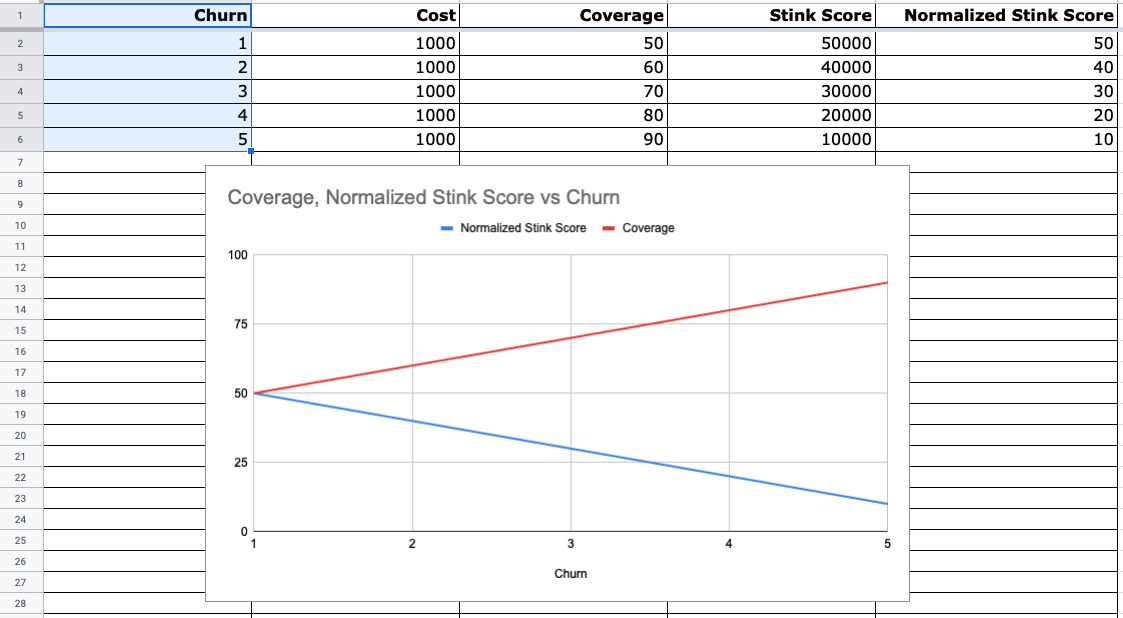
Now the skunk score average makes more sense. 🤓
Fortunately I managed to fix my slides in time for my talk! You can watch my presentation at RubyConf over here:
Conclusion
I believe there is a lot of value in comparing skunk scores between one branch and another. Getting out of the tar pit is no easy feat. You want to make sure that you’re always making changes that get you one step closer to a truly easy-to-maintain project.
In the roadmap for Skunk, I’m really excited about a feature that will keep track of the skunk score average over time. This metric can be our compass in this adventure out of the tar pit. If you see the average going up over time, you will know there is something wrong with your team.
In order to keep improving the tool, I plan to run it using well-established, open source, Ruby and Rails codebases. Which skunk score do you want to see first? Let me know in the comments below! ❤️
SolidusConf
The presentation I gave at SolidusConf was based on Skunk v0.3.0, so there is a mistake in this presentation:
I’m sorry about that, @SolidusConf and attendees! The good news is that it is a small mistake. It doesn’t change much about the core of my talk.
Resources
Here are some of the resources that I used for this article:
- Skunk v0.3.0: https://github.com/fastruby/skunk/tree/v0.3.0
- Skunk v0.3.1: https://github.com/fastruby/skunk/tree/v0.3.1
- gggiiifff.com repository using Skunk v0.3.0: https://github.com/fastruby/gggiiifff.com/tree/skunk-v-0-3-0
- gggiiifff.com repository using Skunk v0.3.2: https://github.com/fastruby/gggiiifff.com/tree/skunk-v-0-3-2
- Skunk Score Playground (Spreadsheet): https://docs.google.com/spreadsheets/d/1yQ2pI5J9XhpI4G884ndIH1NR0g-JCjoitpXS4yaZGFA/edit?usp=sharing